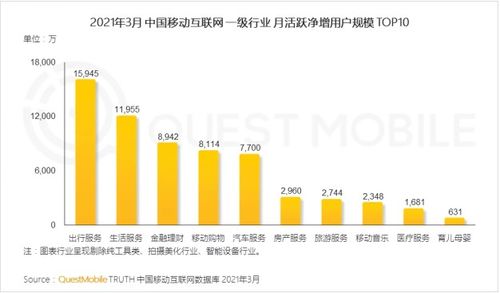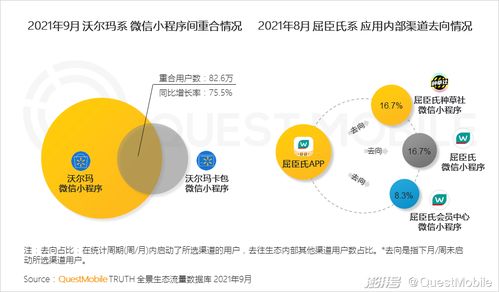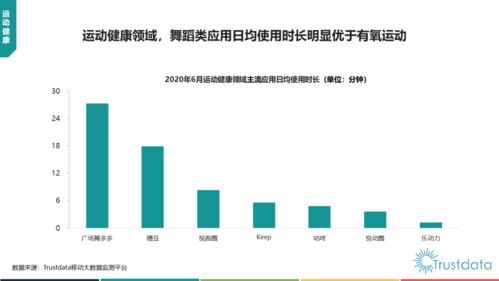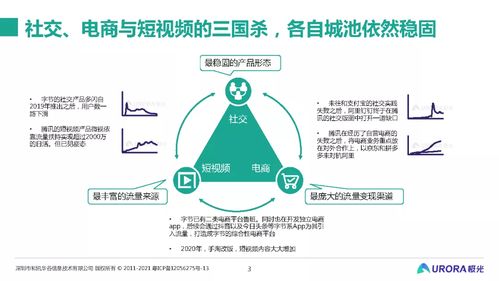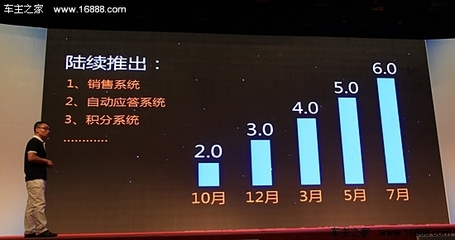
在当今移动互联网高速发展的时代,Google、Amazon、Netflix等全球顶尖互联网公司早已将SRE(Site Reliability Engineering,站点可靠性工程)作为其技术架构的核心支柱。这一角色的兴起并非偶然,而是源于移动互联网研发和维护模式从“传统运维”到“SRE”的深刻变革。SRE之所以比传统运维更抢手,主要基于以下几个关键原因:
SRE实现了研发与运维的深度融合。传统运维往往扮演“救火队”角色,在研发完成后介入,被动响应故障。而SRE从产品设计初期就参与其中,将可靠性、可扩展性和自动化作为核心设计原则。他们不仅负责维护系统稳定,更通过编写代码、设计架构来主动预防问题。例如,通过自动化部署、监控告警和故障自愈系统,SRE能大幅减少人为操作失误,提升服务可用性。在移动互联网领域,用户对App的稳定性和响应速度要求极高,SRE这种“防患于未然”的理念,正是保障亿级用户流畅体验的关键。
SRE以工程化方法量化运维目标。传统运维通常依赖经验判断,而SRE引入如SLI(服务等级指标)、SLO(服务等级目标)和SLA(服务等级协议)等精确度量体系。例如,设定“99.99%的API请求响应时间低于100毫秒”作为SLO,并通过监控数据持续追踪。这使得运维工作从模糊的“保持系统稳定”转变为可衡量、可优化的工程任务。在移动互联网场景中,从用户登录、支付到内容加载,每一个环节的延迟都可能造成用户流失,SRE的数据驱动方法能精准定位瓶颈,提升业务竞争力。
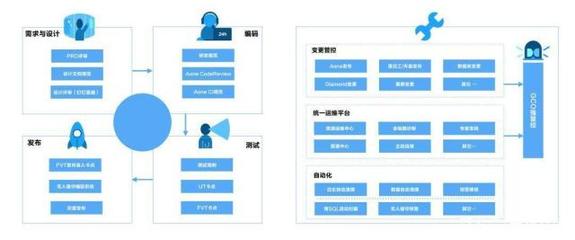
SRE强调自动化与创新。传统运维常陷入重复性手工操作,如服务器配置、日志排查等。SRE则秉承“通过自动化消除琐事”的原则,将至少50%时间投入开发工具和平台,以提升效率。例如,开发统一监控平台、自动化扩容系统和混沌工程工具,模拟故障以增强系统韧性。移动互联网服务需快速迭代,每日可能部署数十次更新,SRE的自动化能力能确保发布既敏捷又可靠。
SRE推动文化变革,倡导“共享责任”。在传统模式中,研发与运维易形成对立;而SRE团队通常由兼具开发与运维技能的工程师组成,他们与研发团队共同承担服务可靠性的责任。这种协作文化加速了问题解决,并鼓励从故障中学习。例如,通过建立“事后分析”机制,将每次事故转化为系统改进的机会。对于移动互联网公司,这种文化能快速适应市场变化,降低运维成本。
市场需求的爆发加剧了SRE的抢手程度。随着云计算、微服务和容器化技术的普及,系统复杂度呈指数级增长,企业急需能驾驭分布式架构的复合型人才。SRE不仅懂运维,还精通编程、网络和数据分析,其稀缺性推高了薪资和职业前景。据统计,国内外头部互联网公司的SRE岗位薪资常比传统运维高出30%-50%,且晋升路径更广。
SRE的崛起标志着运维领域从“手工劳动”到“智能工程”的范式转移。在移动互联网时代,它不仅是技术岗位,更是保障业务持续增长的战略角色。对于企业和从业者而言,拥抱SRE意味着更高效、更可靠的数字未来——这正是为什么SRE正成为技术世界中一颗耀眼的明星。